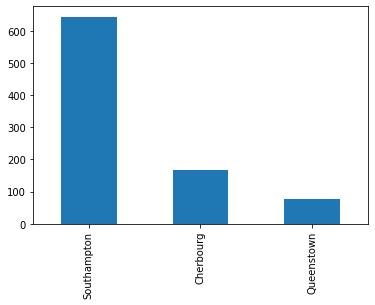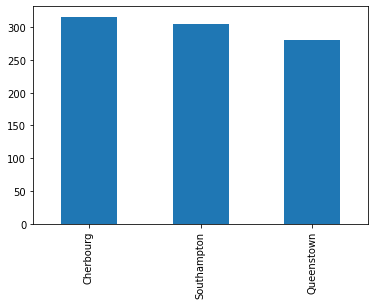#Create a new DataFrame based on filtering criteriadf_2 = df[criteria]
#Assign a new column and print outputdf_2['new column'] ='new value'df_2
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df_2['new column'] = 'new value'
Number
Letter
new column
3
400
d
new value
4
500
e
new value
Using .loc[]
#Create New DataFrame Based on Filtering Criteriadf_2 = df.loc[criteria, :]
#Add a New Column to the DataFramedf_2.loc[:, 'new column'] ='new value'df_2
/Users/fabian/.venv/fastai/lib/python3.8/site-packages/pandas/core/indexing.py:844: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[key] = _infer_fill_value(value)
/Users/fabian/.venv/fastai/lib/python3.8/site-packages/pandas/core/indexing.py:965: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.obj[item] = s
#Create a new DataFrame based on filtering criteriadf_2 = df[criteria].copy()
#Assign a new column and print outputdf_2['new column'] ='new value'df_2
Number
Letter
new column
3
400
d
new value
4
500
e
new value
Conditional assignments
using .map
df['Number'].map({100:1, 200:2})
0 1.0
1 2.0
2 NaN
3 NaN
4 NaN
Name: Number, dtype: float64
using .apply
Similiar to .map but with a function.
def criteria(num):return0if num>300else1
df['Number'].apply(criteria)
0 1
1 1
2 1
3 0
4 0
Name: Number, dtype: int64
Oversampling
Oversampling is a very useful technique that can be used across many contexts to a great effect https://arxiv.org/abs/1710.05381.
from fastai2.tabular.allimport*titanic = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv')titanic.dropna(subset=['embark_town'], inplace=True)